前文已经分析了 HashMap ,根据其实现,了解到其元素无序特性。今天来分析下两个能保证元素顺序的 Map —— 保证插入顺序的 LinkedHashMap 和可自定义排序规则的 TreeMap ,来看看到底是怎么实现有序的。
注:本文基于jdk_1.8.0_162
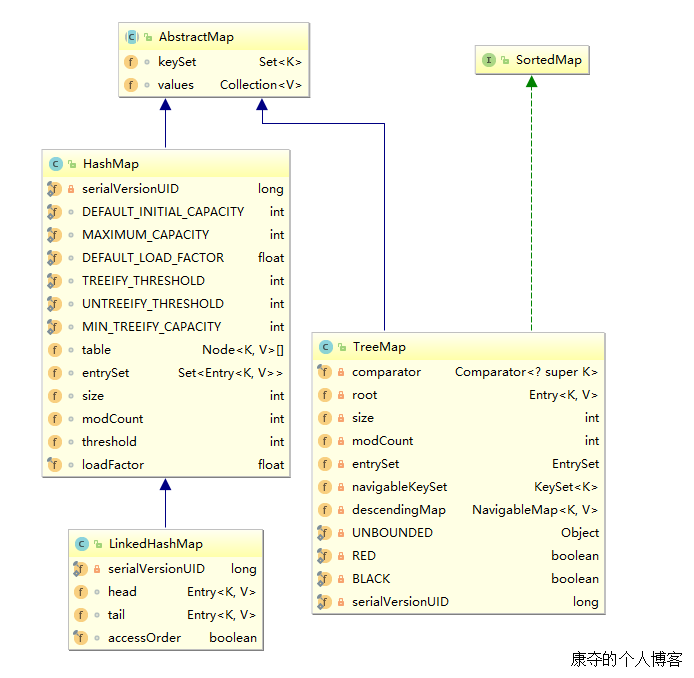
LinkedHashMap 内部结构 总览 LinkedHashMap 是继承自 HashMap 的,或重写或实现了父类中的部分方法,在一定程度上体现了多态。LinkedHashMap 通过多维护了一个插入顺序的链表,保证了元素的访问顺序。同时,属性 accessOrder 可以设置调节元素顺序,便于实现 LRU 算法。
LinkedList = HashMap + LinkedList
主要成员 主要成员如下:
1 2 3 4 5 6 7 8 public class LinkedHashMap <K ,V > extends HashMap <K ,V > implements Map <K ,V > transient LinkedHashMap.Entry<K,V> head; transient LinkedHashMap.Entry<K,V> tail; final boolean accessOrder; }
其中,Entry 的结构如下,继承自 HashMap.Node ,并维护了元素的前后节点信息:
1 2 3 4 5 6 static class Entry <K ,V > extends HashMap .Node <K ,V > Entry<K,V> before, after; Entry(int hash, K key, V value, Node<K,V> next) { super (hash, key, value, next); } }
父类埋点之重点方法 LinkedHashMap 继承自 HashMap ,基本实现上复用父类,具体可参考:Java集合分析之Map-从HashMap说起 。LinkedHashMap 主要实现了 HashMap 中定义了,但是未实现的三个方法:
void afterNodeAccess(Node<K,V> p) { }
void afterNodeInsertion(boolean evict) { }
void afterNodeRemoval(Node<K,V> p) { }
afterNodeAccess 方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 void afterNodeAccess (Node<K,V> e) LinkedHashMap.Entry<K,V> last; if (accessOrder && (last = tail) != e) { LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; p.after = null ; if (b == null ) head = a; else b.after = a; if (a != null ) a.before = b; else last = b; if (last == null ) head = p; else { p.before = last; last.after = p; } tail = p; ++modCount; } }
此方法在 put 和 get 操作时会调用。如果 accessOrder == true ,在 put 之后就算是对元素进行了访问,这时就会更新链表,把该元素放至链表最后。
afterNodeInsertion 方法 1 2 3 4 5 6 7 8 9 10 11 void afterNodeInsertion (boolean evict) LinkedHashMap.Entry<K,V> first; if (evict && (first = head) != null && removeEldestEntry(first)) { K key = first.key; removeNode(hash(key), key, null , false , true ); } } protected boolean removeEldestEntry (Map.Entry<K,V> eldest) return false ; }
这个就是实现 LRU 算法的关键地方了,要实现移除规则,需将 accessOrder 设置为 true 。
afterNodeRemoval 方法 1 2 3 4 5 6 7 8 9 10 11 12 13 void afterNodeRemoval (Node<K,V> e) LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; p.before = p.after = null ; if (b == null ) head = a; else b.after = a; if (a == null ) tail = b; else a.before = b; }
此方法会在移除元素时调用。由于 LinkedHashMap 同时维护了一个双向链表来记录元素顺序,所以,在移除元素的时候,会调整此链表。
这三个方法,就是比 HashMap 多出来的用于维护访问顺序的方法,保证了链表元素从前到后依次是从旧到新。
元素存取方法 put 方法 put 方法并没重写,只是在实现了 afterNodeInsertion 后,记录了元素的插入顺序。有兴趣的可以回看之前的 HashMap 分析文章。
get 方法 1 2 3 4 5 6 7 8 9 public V get (Object key) Node<K,V> e; if ((e = getNode(hash(key), key)) == null ) return null ; if (accessOrder) afterNodeAccess(e); return e.value; }
get 操作就没什么特别的了,和 HashMap 一样的方式取到元素节点。如果设置了 accessOrder ,则维护链表的顺序。
LRU算法 通过上文的分析,我们可以利用 LinkedHashMap 很轻松的实现 LRU 算法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 public class LRUCache <K , V > extends LinkedHashMap <K , V > private Integer maxSize; public LRUCache (Integer maxSize, int initCapacity, float loadFactor) super (initCapacity, loadFactor, true ); this .maxSize = maxSize; } public LRUCache (int maxSize) this (maxSize, 16 , 0.75f ); } public LRUCache () this (Integer.MAX_VALUE); } @Override protected boolean removeEldestEntry (Map.Entry<K,V> eldest) return size() > maxSize; } public static void main (String[] args) Map<String, Integer> cache = new LRUCache<>(3 ); cache.put("aaa" , 1 ); cache.put("bbb" , 1 ); System.out.println(cache); cache.put("ccc" , 1 ); cache.get("aaa" ); System.out.println(cache); cache.put("ddd" , 1 ); System.out.println(cache); } }
运行结果如下,可以看出,元素顺序会在访问时调整,同时也会淘汰最不常用数据。
{aaa=1, bbb=1}
TreeMap 内部构造 总览 TreeMap 继承自 AbstractMap ,实现了 NavigableMap ,根据用户自定义的比较器或者 Key.compareTo 作为排序依据,并使用红黑树来进行实现。
主要成员 1 2 3 4 5 6 7 8 9 10 public class TreeMap <K ,V > extends AbstractMap <K ,V > implements NavigableMap <K ,V >, Cloneable , java .io .Serializable { private final Comparator<? super K> comparator; private transient Entry<K,V> root; private transient int size = 0 ; private transient int modCount = 0 ; }
TreeMap 排序首先看比较器,如果无比较器才会再使用 Key 的比较规则来排序,下文会讲。 Entry 存放的是红黑树的节点数据,数据结构如下:
1 2 3 4 5 6 7 8 static final class Entry <K ,V > implements Map .Entry <K ,V > K key; V value; Entry<K,V> left; Entry<K,V> right; Entry<K,V> parent; boolean color = BLACK; }
节点包含了键值对、父节点、左子节点、右子节点,以及红黑树相关信息。本文只研究 TreeMap 的实现,不具体研究红黑树相关知识。
构造器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public TreeMap () comparator = null ; } public TreeMap (Comparator<? super K> comparator) this .comparator = comparator; } public TreeMap (Map<? extends K, ? extends V> m) comparator = null ; putAll(m); } public TreeMap (SortedMap<K, ? extends V> m) comparator = m.comparator(); try { buildFromSorted(m.size(), m.entrySet().iterator(), null , null ); } catch (java.io.IOException cannotHappen) { } catch (ClassNotFoundException cannotHappen) { } }
元素存取方法 put 方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 public V put (K key, V value) Entry<K,V> t = root; if (t == null ) { compare(key, key); root = new Entry<>(key, value, null ); size = 1 ; modCount++; return null ; } int cmp; Entry<K,V> parent; Comparator<? super K> cpr = comparator; if (cpr != null ) { do { parent = t; cmp = cpr.compare(key, t.key); if (cmp < 0 ) t = t.left; else if (cmp > 0 ) t = t.right; else return t.setValue(value); } while (t != null ); } else { if (key == null ) throw new NullPointerException(); @SuppressWarnings ("unchecked" ) Comparable<? super K> k = (Comparable<? super K>) key; do { parent = t; cmp = k.compareTo(t.key); if (cmp < 0 ) t = t.left; else if (cmp > 0 ) t = t.right; else return t.setValue(value); } while (t != null ); } Entry<K,V> e = new Entry<>(key, value, parent); if (cmp < 0 ) parent.left = e; else parent.right = e; fixAfterInsertion(e); size++; modCount++; return null ; } final int compare (Object k1, Object k2) return comparator==null ? ((Comparable<? super K>)k1).compareTo((K)k2) : comparator.compare((K)k1, (K)k2); }
从 put 方法可以看出,对于 TreeMap 而言,在使用的时候,要么 Key 实现了 Comparable ,要么传入了 Comparator ,这点很重要。同时,其它的一系列操作,基本都会分这两种情况做处理。同时,Comparator 的优先级是高于 Comparable 的。
get 方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 public V get (Object key) Entry<K,V> p = getEntry(key); return (p==null ? null : p.value); } final Entry<K,V> getEntry (Object key) if (comparator != null ) return getEntryUsingComparator(key); if (key == null ) throw new NullPointerException(); @SuppressWarnings ("unchecked" ) Comparable<? super K> k = (Comparable<? super K>) key; Entry<K,V> p = root; while (p != null ) { int cmp = k.compareTo(p.key); if (cmp < 0 ) p = p.left; else if (cmp > 0 ) p = p.right; else return p; } return null ; } final Entry<K,V> getEntryUsingComparator (Object key) @SuppressWarnings ("unchecked" ) K k = (K) key; Comparator<? super K> cpr = comparator; if (cpr != null ) { Entry<K,V> p = root; while (p != null ) { int cmp = cpr.compare(k, p.key); if (cmp < 0 ) p = p.left; else if (cmp > 0 ) p = p.right; else return p; } } return null ; }
get 方法再次印证了,Comparator 的优先级是高于 Comparable 的。
remove 方法 1 2 3 4 5 6 7 8 9 10 11 12 public V remove (Object key) Entry<K,V> p = getEntry(key); if (p == null ) return null ; V oldValue = p.value; deleteEntry(p); return oldValue; }
总结 LinkedHashMap 实际是 HashMap + LinkedListLinkedHashMap 可用来实现 LRU 算法TreeMap 根据使用者定义的排序规则来进行排序,并使用 红黑树 来进行实现TreeMap 的 Key 不可为空,因为需要调用比较器或者 Key 的 compareTo 方法TreeMap 判断是否同一个元素是根据 Comparator 或 Comparable ,而不是 hashcode 和 equalsTreeMap 如果定义了比较器,Key 可以不实现 Comparable 接口TreeMap 比较器规则优先于 Key 的比较规则