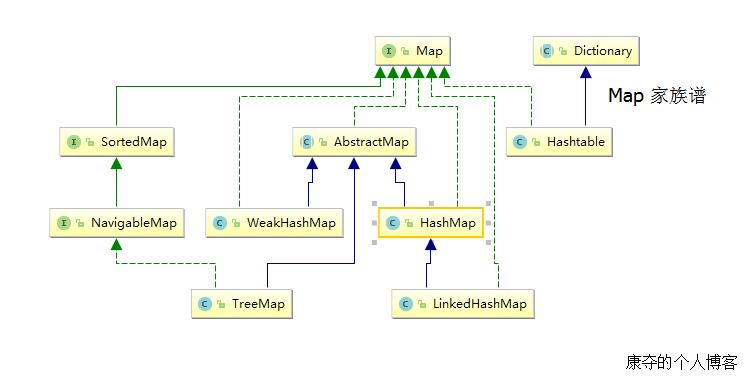
严格来说,Map 并非集合,而是一个键值对的映射。但是 Map 却可以从某些角度被当作集合。Map 当中,最常用的就是 HashMap ,其余几种实现基本都和 HashMap 有关系或者原理一致。
注:本文基于jdk_1.8.0_144
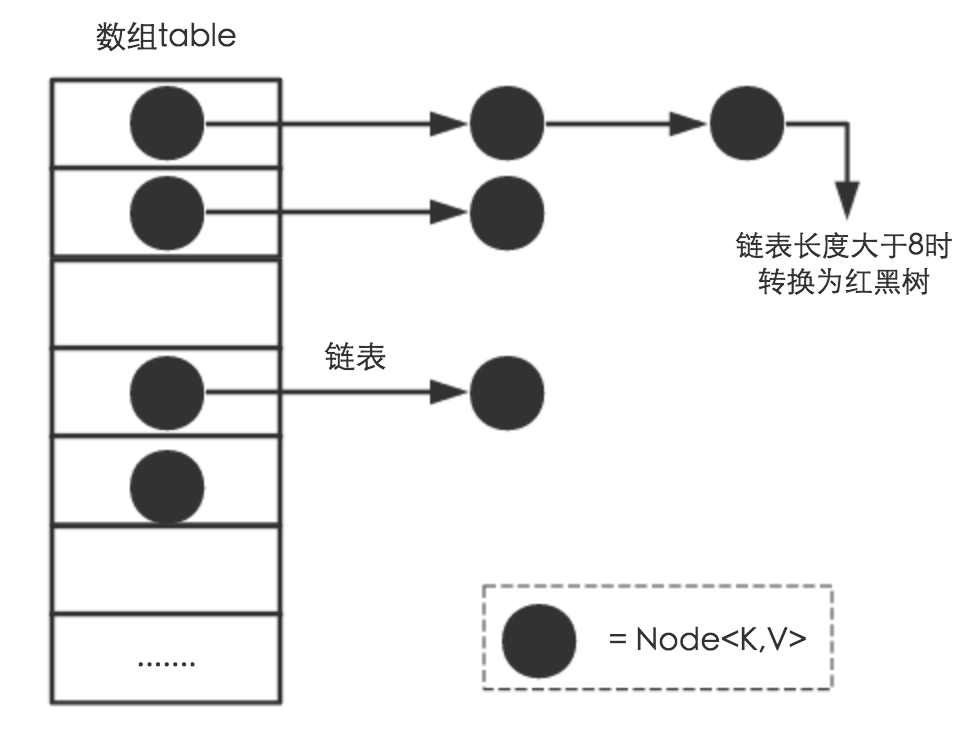
内部结构 总览 HashMap 的内部元素是由一个数组存放,数组类型为 HashMap.Node ,是一个链表。其中,元素所有数组的位置,由 Key 的 hashcode 决定。当然,数组长度有限,hash 值也会有碰撞,如果产生 hash 碰撞,则存于同一个数组下标中,并添加至链表。也就是说,HashMap 的内部实现是,数组+链表。另外,自 JDK1.8 ,对于同一个数组下标位置,如果链表长度过长,会将链表的二叉树转成红黑树(平衡二叉树)。即:
数组 + 链表 + 红黑树
主要成员变量 主要成员变量如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4 ; static final int MAXIMUM_CAPACITY = 1 << 30 ;static final float DEFAULT_LOAD_FACTOR = 0.75f ;static final int TREEIFY_THRESHOLD = 8 ;static final int UNTREEIFY_THRESHOLD = 6 ;static final int MIN_TREEIFY_CAPACITY = 64 ;transient Node<K,V>[] table;transient int size;transient int modCount;int threshold;final float loadFactor;
其中,Node 的结构如下,是一个带有 hash 值及键值对的链表:
1 2 3 4 5 6 static class Node <K ,V > implements Map .Entry <K ,V > final int hash; final K key; V value; Node<K,V> next; }
当链表转化成红黑对的时候,结构如下,LinkedHashMap.Entry 是上面 Node 的子类:
1 2 3 4 5 6 7 static final class TreeNode <K ,V > extends LinkedHashMap .Entry <K ,V > TreeNode<K,V> parent; TreeNode<K,V> left; TreeNode<K,V> right; TreeNode<K,V> prev; boolean red; }
构造器 默认构造器会在初始化的时候,指定加载因子为默认加载因子0.75,容量为0。
1 2 3 public HashMap () this .loadFactor = DEFAULT_LOAD_FACTOR; }
当然,一般我们建议在初始化的时候,能根据情况指定初始容量。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public HashMap (int initialCapacity) this (initialCapacity, DEFAULT_LOAD_FACTOR); } public HashMap (int initialCapacity, float loadFactor) if (initialCapacity < 0 ) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); this .loadFactor = loadFactor; this .threshold = tableSizeFor(initialCapacity); }
可以看出,如果指定了初始容量,会进行容量的重计算,保证初始容量是2的N次方。
1 2 3 4 5 6 7 8 9 static final int tableSizeFor (int cap) int n = cap - 1 ; n |= n >>> 1 ; n |= n >>> 2 ; n |= n >>> 4 ; n |= n >>> 8 ; n |= n >>> 16 ; return (n < 0 ) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1 ; }
那么这个算法是怎么保证得到的是2的N次方的呢?
对于容量 cap ,在转化成二进制之后,总会找到第一个 1 ,如 01xxxxxx 在和自身右移一位做或运算之后,能保证第一个 1 的后面一位也是 1 ,这样就有连续的两位是 1 了,即 01xxxxxx | 001xxxxx = 011xxxxx 同理,依次做或运算之后,能保证最高是 1 的那一位之后的所有位都是 1 ,即 011xxxxx | 00011xxx = 01111xxx ,直至得到 01111111 最后,再进行 n + 1 就得到了大于当前数的下一个2的N次方 第一步的 n = cap - 1 是为了让本身是2的N次方的数,得到的结果还是自己 hash 值计算及索引定位 HashMap 在进行 put 和 get 操作时,是把键值对放至 table 数组的特定下标位。
其中索引位置是这样计算出来的:
1 2 int n = table.lengthint index = (n - 1 ) & hash
其中,hash 是将 key 通过下面的方法算出来的。
1 2 3 4 static final int hash (Object key) int h; return (key == null ) ? 0 : (h = key.hashCode()) ^ (h >>> 16 ); }
那么问题来了,hash 值为什么要这样算?索引计算到底表示什么意义?
索引计算 通过上面我们知道,HashMap 的数组容量大小始终是2的N次方。n 表示的数组的长度,所以 n - 1 得到的二进制,后面的值一定是连续的 1 ,在与 hash 做与运算之后,得到的实际是 hash 对 n 的取余。
如,某数对16取余:
0100 1110 1101 0011
所以,(n - 1) & hash == hash % n 。当然,这是有前提的,n 必须为2的N次方。
hash 值计算 我们明明可以直接用 key.hashCode() ,为什么还要做个异或操作呢?
由于 HashMap 的 Key 的 hashCode() 方法是不确定的,所以,某些自定义类型的 Key ,有可能会得到一些尾数具有重复性的 hashcode 。这时候,将 hashcode 的高16位与低16位进行异或,就会减少 hash 碰撞。
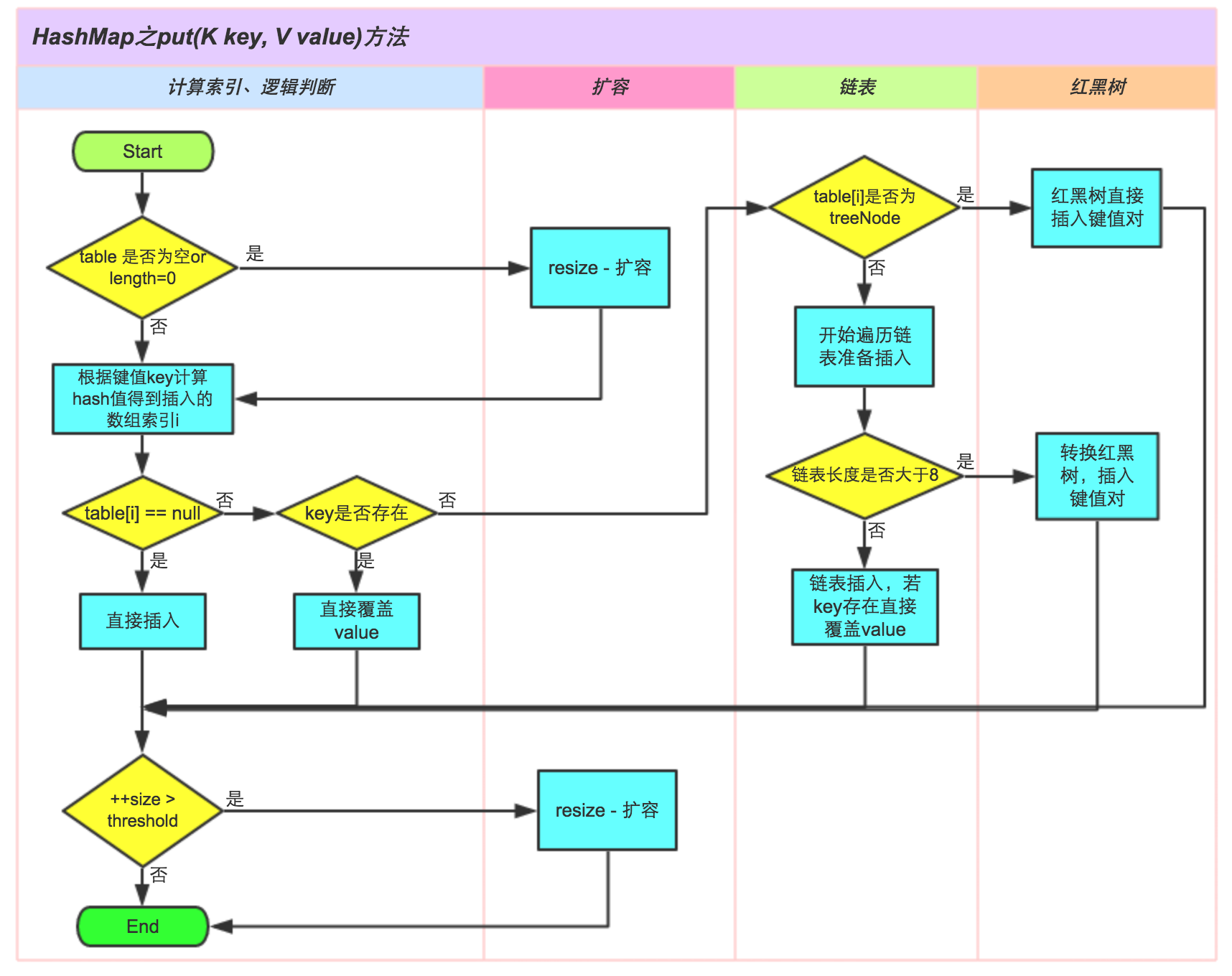
put 操作 借用一张来自美团的图,put 流程如下:
还是对照下源码来对照理解吧。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 public V put (K key, V value) return putVal(hash(key), key, value, false , true ); } final V putVal (int hash, K key, V value, boolean onlyIfAbsent, boolean evict) Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0 ) n = (tab = resize()).length; if ((p = tab[i = (n - 1 ) & hash]) == null ) tab[i] = newNode(hash, key, value, null ); else { Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this , tab, hash, key, value); else { for (int binCount = 0 ; ; ++binCount) { if ((e = p.next) == null ) { p.next = newNode(hash, key, value, null ); if (binCount >= TREEIFY_THRESHOLD - 1 ) treeifyBin(tab, hash); break ; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break ; p = e; } } if (e != null ) { V oldValue = e.value; if (!onlyIfAbsent || oldValue == null ) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; if (++size > threshold) resize(); afterNodeInsertion(evict); return null ; }
注:红黑树本文不讨论是怎么实现的,头大。
get 操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 public V get (Object key) Node<K,V> e; return (e = getNode(hash(key), key)) == null ? null : e.value; } final Node<K,V> getNode (int hash, Object key) Node<K,V>[] tab; Node<K,V> first, e; int n; K k; if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1 ) & hash]) != null ) { if (first.hash == hash && ((k = first.key) == key || (key != null && key.equals(k)))) return first; if ((e = first.next) != null ) { if (first instanceof TreeNode) return ((TreeNode<K,V>)first).getTreeNode(hash, key); do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } while ((e = e.next) != null ); } } return null ; }
这里面有个不大不小的坑,如果 key 的设计和使用不当,会引起不必要的bug:在查找数据的时候,是直接去指定下标进行查找的,如果当前索引查找不到,则返回结果为 null 。
看起来好像没毛病,那么下面这种情况呢?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public class User private String username; private Integer age; @Override public int hashCode () return age; } } public class Test public static void main (String[] args) Map<User, String> testMap = new HashMap<User, String>(); User user = new User(); user.setUsername("Tom" ); user.setAge(18 ); testMap.put(user, user.getUsername() + " is a good child" ); System.out.println("exists : " + testMap.get(user)); user.setAge(22 ); System.out.println("exists : " + testMap.get(user)); } }
输出结果很明显,同一个 key ,后来查找不到了:
exists : Tom is a good child
exists : null
resize 扩容 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 final Node<K,V>[] resize() { Node<K,V>[] oldTab = table; int oldCap = (oldTab == null ) ? 0 : oldTab.length; int oldThr = threshold; int newCap, newThr = 0 ; if (oldCap > 0 ) { if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; } else if ((newCap = oldCap << 1 ) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1 ; } else if (oldThr > 0 ) newCap = oldThr; else { newCap = DEFAULT_INITIAL_CAPACITY; newThr = (int )(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); } if (newThr == 0 ) { float ft = (float )newCap * loadFactor; newThr = (newCap < MAXIMUM_CAPACITY && ft < (float )MAXIMUM_CAPACITY ? (int )ft : Integer.MAX_VALUE); } threshold = newThr; @SuppressWarnings ({"rawtypes" ,"unchecked" }) Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; table = newTab; if (oldTab != null ) { for (int j = 0 ; j < oldCap; ++j) { Node<K,V> e; if ((e = oldTab[j]) != null ) { oldTab[j] = null ; if (e.next == null ) newTab[e.hash & (newCap - 1 )] = e; else if (e instanceof TreeNode) ((TreeNode<K,V>)e).split(this , newTab, j, oldCap); else { Node<K,V> loHead = null , loTail = null ; Node<K,V> hiHead = null , hiTail = null ; Node<K,V> next; do { next = e.next; if ((e.hash & oldCap) == 0 ) { if (loTail == null ) loHead = e; else loTail.next = e; loTail = e; } else { if (hiTail == null ) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null ); if (loTail != null ) { loTail.next = null ; newTab[j] = loHead; } if (hiTail != null ) { hiTail.next = null ; newTab[j + oldCap] = hiHead; } } } } } return newTab; }
前文说的下面几点很重要:
存放元素的数组,容量永远是2的N次方 元素存放在数组中的索引位置,实际是 hash 对数组容量进行取余 之所以是等效于取余,是因为 hash 的尾部与 1 做 & 运算会保持原来的值 对于链表只有一个节点的情况,直接查找索引位置重定位就可以了;而如果链表有多个节点的话,难道所有的节点都重新计算一下索引位置吗?并不是这样的,按照源码可以看出是这样子的:
如果 (e.hash & oldCap) == 0 ,重组一个新链表 A 如果 (e.hash & oldCap) != 0 ,再组一个新链表 B 新链表 A ,索引位置是 原位置 新链表 B ,索引位置是 原位置 + 旧2的N次方 那么问题来了,为什么一个链表要拆成两个?为什么索引位置只有这两个位置,而不需要全部重新计算?通过上面说的几点可以解答:( n 指扩容前数组大小)
数组扩容后,大小是原来的2倍,索引位置仍然是进行取余操作,只不过是对 2n 取余 同一个数字,由对 n 取余,变成对 2n 取余后,结果要么不变,要么变了;如果变了,只有一种可能,就是加大了 n 什么情况下会加大 n 呢,通过前面描述的取余是与 1 对应位做与操作,oldCap 是2的N次方, 可以得出结论: (e.hash & oldCap) == 0 时,说明原来的 hash 的低N位上的二进制数字是 0 ,所以索引位置不变;同理,(e.hash & oldCap) != 0 ,说明原来的 hash 的低N位上的数字是 1 ,新索引位置要加 oldCap 了 线程安全性 HashMap 是个非线程安全的类,所以,在多线程情况下,应尽量避免直接使用 HashMap ,换成 ConcurrentHashMap 或者 Collections.synchronizedMap(hashmap) 。为什么说 HashMap 非线程安全呢?
resize() 造成死循环 参考 :疫苗:JAVA HASHMAP的死循环
其实,这个问题在 JDK1.8 已经被修复了 。死循环的原因是 resize() 时链表的倒序引起的,但是在 JDK1.8 中,插入元素并会再插入链表头部了,resize() 时也不会倒排了。
put 时某线程被覆盖 举个例子,在上述的 put操作 部分,有一行源码如下:
1 tab[i] = newNode(hash, key, value, null );
比如,两个线程同时走到这里,分别执行此行代码,就会有一个线程的数据丢了。
modCount 相关的 fail-fast 关于 modCount ,之前的一篇文章中有提过,参考这里:modCount 是干什么的
在 Map 中也有同样的机制,在进行某些操作的时候,会检查 modCount 。如果 modCount 与预期不一样,就会抛 ConcurrentModificationException 。
所以,如果同时有两个线程操作同一个 HashMap ,一个线程在遍历,一个线程在 put 。这个时候就有可能导致 modCount 校验不通过,从而引起异常。这显然不是我们想要的结果,不符合我们的预期。
总结 HashMap 实际是 数组 + 链表 + 红黑树HashMap 键可以为 null ,值也可以为 nullHashMap 在查找值的时候,是根据 key 的 hash 来确定位置的,所以,key 一定尽可能用不可变类。一旦 put 后再改变 key 的 hash ,就会出现 get 不到结果的情况数组容量一定是2的N次方,默认负载因子0.75,尽量不要动 扩容消耗很大,所以初始化的时候尽量指定一个合适的容量 HashMap 非线程安全,多线程下请使用 ConcurrentHashMap 或者 Collections.synchronizedMapJDK1.8 中引入了红黑树,在 hash 冲突高及元素数量特殊大的时候,效率高。