Stream 提供了 reduce 方法,顾名思义,是将流内的元素按照一定的规则汇聚成一个值。
在了解 reduce 之前,我们来先思考一个问题:我们需要哪些内容才能完成汇聚操作?
- 数据
- 汇聚结果类型
- 汇聚方案
而 Stream 本身就是数据源,所以我们只要专注思考我们想要什么类型的返回数据,以及怎么样把数据汇聚起来。
reduce(BinaryOperator)
方法定义
Optional<T> reduce(BinaryOperator<T> accumulator)
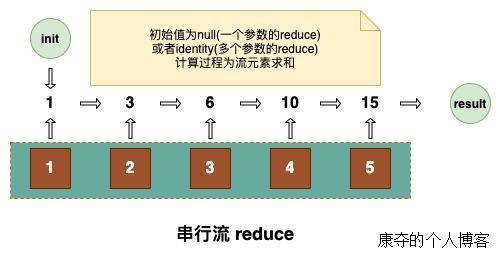
这个方法的入参 BinaryOperator,是一个二元操作的函数式接口,也就是提供了数据汇聚的方案。reduce 的过程是分而治之的过程,这个过程不是一步完成的,是元素两两合并,结果再两两合并,直到有最终结果,返回类型为 Optional。
其实这部分在 JavaDoc 里用代码解释的很明白,计算得到的初始值用的是取到的第一个元素。整体过程是把流所有的元素合并成一个值,合并的规则是在 accumulator.apply 里定义的。
1 | boolean foundAny = false; |
使用举例
1 | public void reduceTest1() { |
两个调用,第一处是求和,第二处是求最大值,分别输出如下:
sum result is 15
max num is 5
reduce(T, BinaryOperator)
方法定义
T reduce(T identity, BinaryOperator<T> accumulator);
这个 reduce 方法有两个参数。第一个参数给的是一个初始默认值,第二个参数还是计算逻辑。与单参数的 reduce 相比,这个方法多了初始默认值,同时因为有了默认初始默认值,返回类型不再是 Optional,而是具体的类型。
在 JavaDoc 中,同样以代码的形式生动的讲述了这个方法的处理过程。
1 | T result = identity; |
使用举例
1 | public void reduceTest2() { |
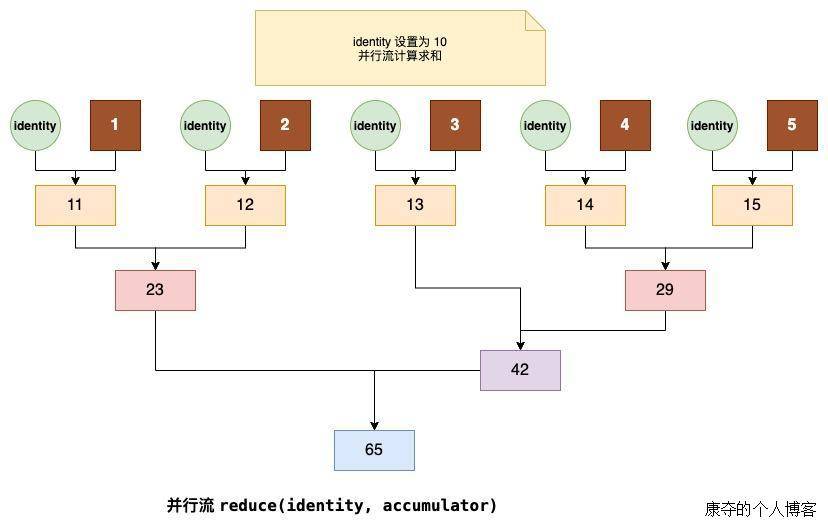
在这里,我们设置了默认初始值为 10,同时分别用串行流和并行流进行计算,但是意外的是,结果并不相同。
串行流求和结果为:25
并行流求和结果为:65
并行流探究
1 | Integer reduce = integers.parallelStream().reduce(10, (a, b) -> { |
在执行过程中,我们打印出了每一步的过程变量及计算结果,输出如下:
ForkJoinPool.commonPool-worker-9 : a = 10, b=4, sum=14
ForkJoinPool.commonPool-worker-7 : a = 10, b=1, sum=11
ForkJoinPool.commonPool-worker-3 : a = 10, b=5, sum=15
ForkJoinPool.commonPool-worker-5 : a = 10, b=2, sum=12
ForkJoinPool.commonPool-worker-3 : a = 14, b=15, sum=29
ForkJoinPool.commonPool-worker-5 : a = 11, b=12, sum=23
main : a = 10, b=3, sum=13
main : a = 13, b=29, sum=42
main : a = 23, b=42, sum=65
并行流求和结果为:65
可以看出,并行流计算是在多线程下计算,且初始值对于每个流元素而言都重复计算了一遍,这就导致了计算结果与我们预期的不一致。
其实在 JavaDoc 中,关于这一点也有注释说明。因为不同的线程都会利用这个值计算,所以这个 identity 在并行流时不应该成为影响因素。为了消除这个影响,需要保证 accumulator.apply(identity, t) 的计算结果仍然是 t,这样才不会对最终结果产生影响。
reduce(U, BiFunction, BinaryOperator)
方法定义
<U> U reduce(U identity,
BiFunction<U, ? super T, U> accumulator,
BinaryOperator<U> combiner);
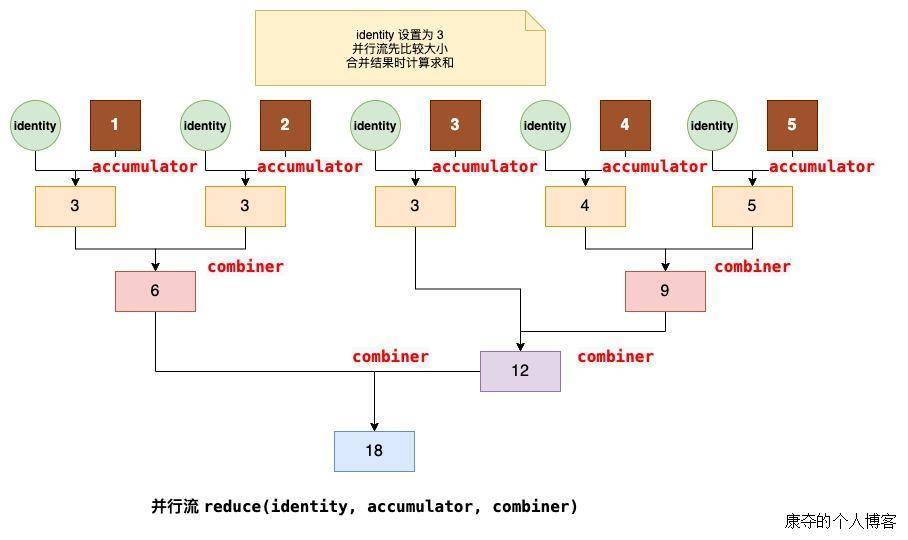
相比二参数方法,这里多了第三个参数 combiner,这个 combiner 是用来合并多线程计算的结果。
在并行流计算时,会有多线程共同来处理流元素。每个线程做完 reduce 之后都有自己的处理结算 result,而 combiner 的作用就是合并每个线程的 result 并得到最终结果。
使用举例
并行流
1 | public void reduceTest3() { |
为了了解每个参数内到底在做什么,我们打印出了处理过程,并用符号区分不同方法打印出来的结果,输出如下:
main: i1 = 3, i2 = 3, result = 3
ForkJoinPool.commonPool-worker-7: i1 = 3, i2 = 1, result = 3
ForkJoinPool.commonPool-worker-7: i1 = 3, i2 = 4, result = 4
ForkJoinPool.commonPool-worker-3: i1 = 3, i2 = 2, result = 3
ForkJoinPool.commonPool-worker-5: i1 = 3, i2 = 5, result = 5
ForkJoinPool.commonPool-worker-3# i3 = 3, i4 = 3, result = 6
ForkJoinPool.commonPool-worker-5# i3 = 4, i4 = 5, result = 9
ForkJoinPool.commonPool-worker-5# i3 = 3, i4 = 9, result = 12
ForkJoinPool.commonPool-worker-5# i3 = 6, i4 = 12, result = 18
final result is 18
由输出结果,我们发现,第二个参数 accumulator 实际上只做对于 identity 和初始流元素的 reduce,得到的结果后续全交由 combiner 来继续 reduce。
串行流
1 | public void reduceTest4() { |
这一次使用串行流,以同样的方法打印输出结果:
main: i1 = 3, i2 = 1, result = 3
main: i1 = 3, i2 = 2, result = 3
main: i1 = 3, i2 = 3, result = 3
main: i1 = 3, i2 = 4, result = 4
main: i1 = 4, i2 = 5, result = 5
final result is 5
好家伙,果然不再并行处理,但是问题来显现出来,第三个参数没起任何作用,由第二个参数以串行的方式对所有元素取较大值了。
总结
- reduce 是分而治之的处理思想,不是一步就完成的,并行流的情况下效率会更高一些。
- reduce 的 identity 参数,在并行流下会重复参与计算的,可能会对结果产生影响。如果要消除影响,要保证
accumulator.apply(identity, t)的结果还是t。 - reduce 在并行流中,底层是通过
ForkJoinPool来处理数据的。 - reduce 方法的第三个参数
combiner在串行流下是不参与处理的,仅由第二个参数提供的函数式接口来处理。 - reduce 方法的第三个参数会处理由第二个参数处理完的结果,将所有的结果
combiner成一个结果,也就是Fork/Join的join。